In this article, let’s continue talking about Kubernetes workloads. Let’s get started!
Kubernetes Workloads
A workload is an application running on Kubernetes.
Pods
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes. Kubernetes pods have a defined lifecycle.
Pods in a Kubernetes cluster are used in two main ways:
- Pods that run a single container. The “one-container-per-Pod” model is the most common Kubernetes use case; in this case, you can think of a Pod as a wrapper around a single container; Kubernetes manages Pods rather than managing the containers directly.
- Pods that run multiple containers that need to work together. A Pod can encapsulate an application composed of multiple co-located containers that are tightly coupled and need to share resources. The Pod wraps these containers, storage resources, and an ephemeral network identity together as a single unit.
Imperative way of creating a pod:
kubectl run <pod-name> --image=<image-name>
A sample nginx pod YAML file (i.e declarative way):
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
ReplicaSet
A ReplicaSet is used for making sure that the designated number of pods is up and running. It is convenient to use when we are supposed to run multiple pods at a given time.
ReplicaSet requires labels to understand which pods to run, a number of replicas that are supposed to run at a given time, and a template of the pod that it needs to create.
So let’s check it in the YAML file:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx
labels:
app: nginx
tier: lb
spec:
replicas: 3
selector:
matchLabels:
tier: lb
template:
metadata:
labels:
tier: lb
spec:
containers:
- name: nginx-replicaset
image: nginx
Please note that it is not using apiVersion “v1” but “apps/v1”. We define a label in replica set metadata and use it as a selector under spec. With Replicas ( spec.replicas) we defined the number of replicas that should be up and running. And on the template ( spec.template), we put the information about the pod that we want to be created.
To see it in action let’s apply this YAML file.
kubectl apply -f replicaset.yaml
![]()
And let’s check the pods:
kubectl get pods
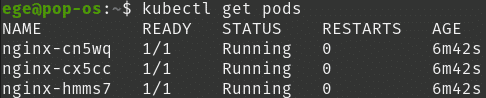
Please observe that it takes the name of the replica set and attaches a random value next to it as a pod name ( i.e nginx-cn5wq).
Let’s see the replica set in action by forcefully deleting a pod.
kubectl delete pod nginx-cn5wq
![]()
And if we check the pods again a new one should be created ( check AGE section ):
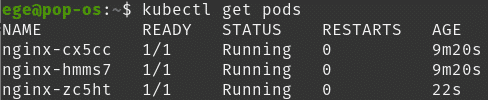
For checking the replica set:
kubectl get replicasets
or
kubectl get rs
for short.

Deployments
Deployment is the abstraction layer on top of ReplicaSet and Pod. It means it can both control the number of replicas and the template of pods. So unlike a ReplicaSet, which only controls the number of replicas, changes you make on the Pod template will update the Pod.
A Deployment will create a ReplicaSet and Pod(s). Kubernetes suggests usage of Deployment rather than a ReplicaSet unless otherwise required.
Deployment can be created imperatively:
kubectl create deployment nginx --image=nginx --replicas=2
![]()
And we can observe the pods and the replica set.
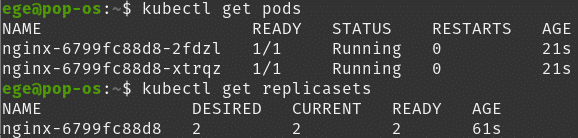
And with the declarative way ( taken from documentation: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#creating-a-deployment ):
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
To get the deployments the command is:
kubectl get deployments

You can also see deployment rollout status by:
kubectl rollout status deployment nginx
![]()
StatefulSets
StatefulSet is the workload API object used to manage stateful applications. Manages the deployment and scaling of a set of Pods, and provides guarantees about the ordering and uniqueness of these Pods.
It sounds a lot like Deployment but the difference is StatefulSet provides uniqueness to the Pods, unlike Deployment. This eventually means if our application is stateful we are supposed to use, as the name suggests, StatefulSets because with Deployment Pods rescheduled will not maintain a stable identity.
StatefulSets are valuable for applications that require one or more of the following.
- Stable, unique network identifiers.
- Stable, persistent storage.
- Ordered, graceful deployment and scaling.
- Ordered, automated rolling updates.
The way Kubernetes maintain a stable identity is by using persistent volumes. We will talk about it later in this tutorial in this chapter ( i.e Kubernetes Objects ). A StatefulSet application also needs a service to be exposed which we haven’t covered yet as well so for now just take a look at this example on how to create a statefulset:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
To get the statefulset:
kubectl get statefulsets
DaemonSets
The last object on workloads we will talk about will be DaemonSets.
A DaemonSet, as the name suggests, works as a daemon on each node and ensures that each node runs the Pod specified. So as you add a new node to your cluster DaemonSet defined will create the Pod. Those Pods will only be deleted by removing the node or deleting the DaemonSet.
You may wonder why we would need such an object. In can be listed as:
- running a cluster storage daemon on every node
- running a logs collection daemon on every node
- running a node monitoring daemon on every node
Let’s create an nginx daemonset with the following YAML:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx
spec:
selector:
matchLabels:
name: nginx-lb
template:
metadata:
labels:
name: nginx-lb
spec:
containers:
- name: nginx
image: nginx
kubectl apply -f daemonset.yaml
![]()
Now we can observe both daemonset and pods on each worker node. The command to get daemonsets:
kubectl get daemonsets
or for short:
kubectl get ds

Please note by default daemonset pods are not being scheduled on the master node. But you can add toleration for it to run on the master node as well.
Kubernetes Series
- Episode 1: Introduction to Kubernetes
- Episode 2: How to Create a Kubernetes Cluster
- Episode 3: Kubectl
- Episode 4.1: Kubernetes Objects
- Episode 4.2: Kubernetes Workloads
- Episode 4.3: Kubernetes Services
- Episode 4.4: Kubernetes Storage
- Episode 4.5: Kubernetes Configuration Objects
- Episode 5: Scheduling in Kubernetes
- Episode 6: Kubernetes Upgrade and Deployment Strategies
- Episode 7: Kubernetes Security
- Episode 8: Deploy a Full Stack Application in Kubernetes
Thanks for reading,
Ege Aksoz

Holding a BSc in Mechatronics, Ege loves to automate. He is now working as a Software Development Engineer In Test at XebiaLabs, Amsterdam.